这期内容当中小编将会给大家带来有关PostgreSQL中怎么实时干预搜索排序,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
PostgreSQL是一个历史悠久的数据库,最早由加州大学伯克利分校的Michael Stonebraker教授领导设计,具备与Oracle类似的功能、性能、架构以及稳定性。
阿里云HybridDB for PostgreSQL,提供大规模并行处理(MPP)数据仓库服务, 支持多核并行计算、向量计算、图计算、JSON,JSONB全文检索。
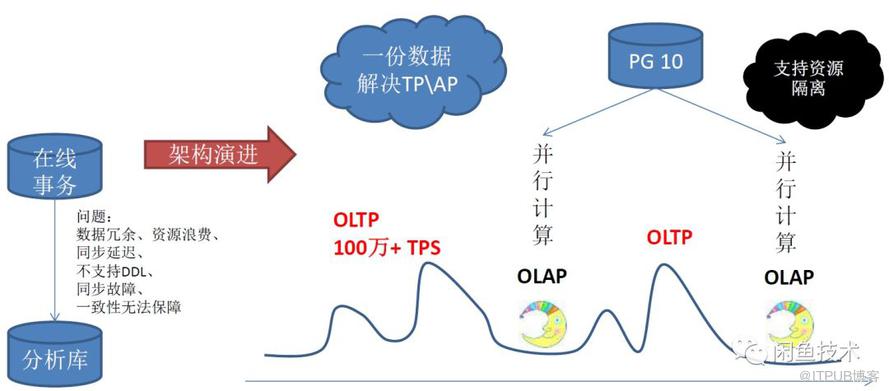
PostgreSQL高效的并行处理能力,基于JSON格式数据合并能力以及Notify实时消息能力,给我们提供了具体实现思路。因此基于上文提到业务挑战,我们梳理了相关实现方案。
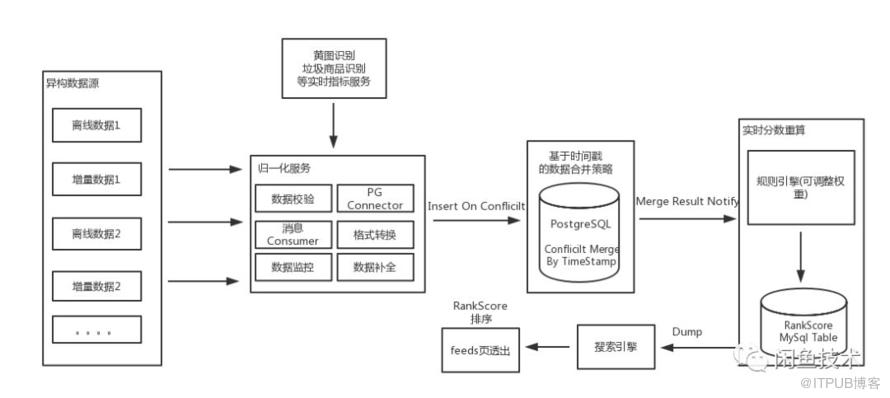
仔细分析整体方案,归纳起来涉及的方面有:
异构数据源接入
归一化服务
数据合并策略
实时分数重算
闲鱼商品相关的数据非常丰富,有各种异构数据源,如全量的离线商品数据,实时商品变更数据,各种算法维度数据等,在实现上可通过阿里云大数据平台,binlog监听工具等进行统一处理。
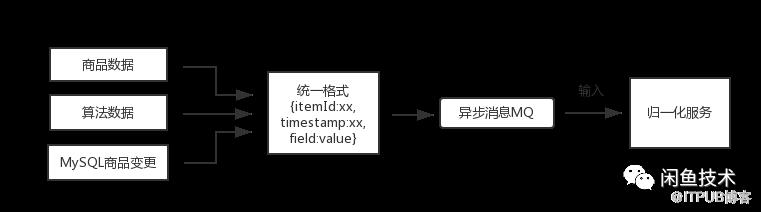
如上图所示,所有异构数据源都按照统一格式,通过异步消息,输入到归一化服务,该方案的优点是不管全量数据还是增量数据都统一走消息服务,简化接入流程,同时通过消息中间层进行解耦,提高稳定性。
归一化服务接收上游异构数据源消息,通过数据校验模块、数据补全模块、标准格式转换模块、数据监控模块为下游输送正确的数据。
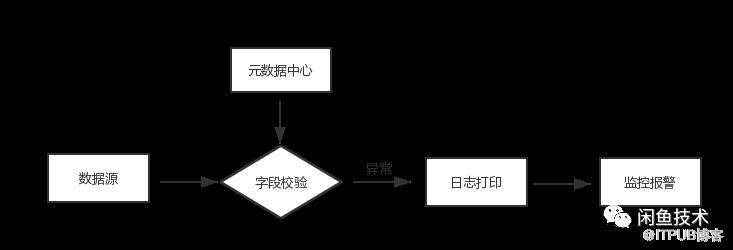
数据校验模 如下图所示,数据源结合元数据中心进行字段级别的校验,如字段名称,数据类型,数据范围、默认值等,引入元数据中心最大优势是可以细粒度的控制数据源,防止脏数据、不需要的数据污染下游。
数据补全模块 数据源通常需要实时补全一些数据干预指标,如用户编辑商品,需实时分析打标是否有黄图,商品价格预测等,整个干预流程要以pipeline的形式,暴露扩展点,允许插入干预能力。
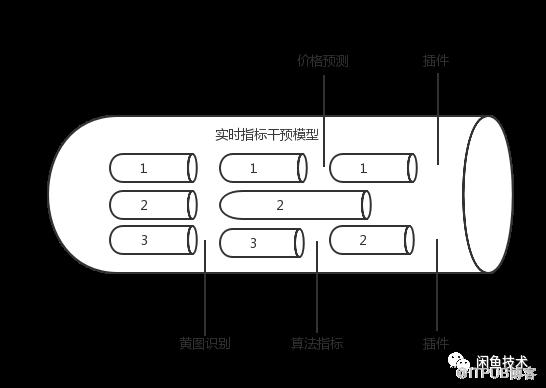
标准格式转换模块 标准格式转换模块将数据源统一按标准的格式转换成JSON结构,便于下游统一数据合并。
数据监控模块 数据监控模块记录数据源的每一条数据以及异常数据记录,并将数据投递到监控系统,监控每个异构数据源异常数据,流量异常情况,第一时间发现并恢复问题。
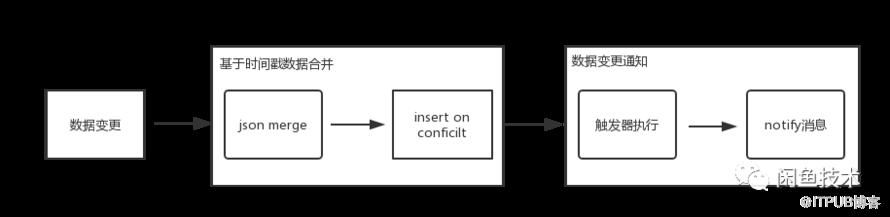
数据合并策略主要包括基于时间戳的数据合开和数据变更通知两个先后处理流程,在数据合并流程会遇到一个核心问题,即如何快速有效的解决每个字段的冲突合并,基于时间戳统一merge。这里首先会涉及到数据存储结构,参考如下表设计结构:
create table Test (id int8 primary key, -- 商品IDatt jsonb -- 商品属性);
属性设计为JSON,JSON里面是K-V的属性对,如下属性结构示例,V里面是数组,包含K的值以及这对属性的最后更新时间,更新时间用于merge update,当属性发生变化时才更新,没有发生变化时,不更新。这种设计优点:
字段级别细粒度merge,保证最小集数据实时性
高扩展性,表不需要增减字段
属性结构示例
{"count": [100, "2017-01-01 10:10:00"], "price": [8880, "2018-01-04 10:10:12"], "newatt": [120, "2017-01-01 12:22:00"]}定义完存储结构, 接下来利用PostgreSQL的JSON处理能力进行数据merge,参考如下merge udf 伪代码:
create or replace function merge_json(jsonb, jsonb) returns jsonb as $$ select jsonb_object_agg(key,value) from ( select coalesce(a.key, b.key) as key, case when coalesce(jsonb_array_element(a.value,1)::text::timestamp, '1970-01-01'::timestamp) > coalesce(jsonb_array_element(b.value,1)::text::timestamp, '1970-01-01'::timestamp) then a.value else b.value end from jsonb_each($1) a full outer join jsonb_each($2) b using (key) ) t; $$ language sql strict ;
定义完merge方法后,我们在数据源有数据变更时直接调用。
insert into a values
(1, '{"price":[1000, "2019-01-01 10:10:12"], "newatt": ["hello", "2018-01-01"]}')
on conflict (id)
do update set
att = merge_json(a.att, excluded.att)
where
a.att <> merge_json(a.att, excluded.att);从上面可以看出当商品ID出现冲突时,会调用merge_json 进行数据合并,至此数据合并流程完成,接下来需要将合并结果实时通知下游,可以利用PostgreSQL的触发品和Notify机制来处理。
触发器设计
//触发器要执行的udf
CREATE OR REPLACE FUNCTION notify1() returns trigger AS $function$
declare
begin
perform pg_notify(
'a', -- 异步消息通道名字
format('CLASS:notify, ID:%s, ATT:%s', NEW.id, NEW.att) -- 消息内容
);
return null;
end
$function$ language plpgsql strict;
//创建触发器
create trigger tg1 after insert or update on Test for each row execute procedure notify1();可以看出当数据插入或更新会触发trigger 执行nofity1 函数创建异步nofity消息,并向指定的通道发送通知,下游应用可通过jdbc监听相应的通道,接收消息,进行后续实时打分流程,参考如下伪代码:
this.pgconn = conn.unwrap(org.postgresql.PGConnection.class);
Statement stmt = conn.createStatement();
stmt.execute("LISTEN a");
stmt.close();
org.postgresql.PGNotification notifications[] = pgconn.getNotifications();
if (notifications != null) {
for (int i=0; i < notifications.length; i++) {
System.out.println("Got notification: " + notifications[i].getName());
}
}另外PostgreSQL并发处理性能非常高效,绑定触发器后会增加PostgreSQL的数据写入时长,但是压测结果来看,依然能够满足我们的业务写入性能要求,
以1000万数据测试结果为例:

数据实时打分干预搜索
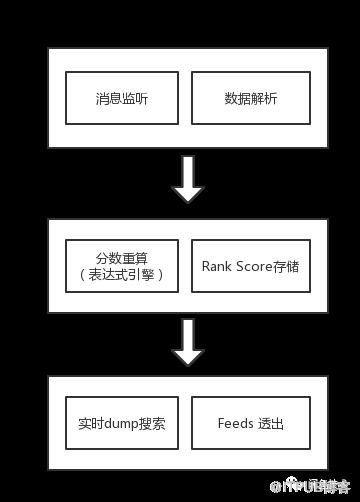
服务层在监听到Notify消息,解析消息数据,通过规则引擎对各指标权重进行分数重算,计算综合分数,打到搜索tag表,搜索引擎实时监测tag表,将综合分数dump到搜索引擎,实时干扰排序结果。
上述就是小编为大家分享的PostgreSQL中怎么实时干预搜索排序了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注捷杰建站行业资讯频道。
本站采用系统自动发货方式,付款后即出现下载入口,如有疑问请咨询在线客服!
售后时间:早10点 - 晚11:30点
 服务热线 19970861797
服务热线 19970861797

 返回顶部
返回顶部