这篇“Python怎么通过手肘法实现k_means聚类”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“Python怎么通过手肘法实现k_means聚类”文章吧。
import matplotlib.pylab as plt import numpy as np
# 计算两点距离 def distance(a, b): return np.sqrt((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2)
# 取集合中心点 def means(arr): x = 0 y = 0 for i in range(len(arr)): x += arr[i][0] y += arr[i][1] if len(arr) > 0: x /= len(arr) y /= len(arr) return np.array([x, y])
# 寻找距离已加入聚类中心数组最远的点,用于初始化聚类中心 def farthest(k_arr, arr): point = [0, 0] max_dist = 0 for e in arr: dist = 0 for i in range(len(k_arr)): dist += distance(k_arr[i], e) if dist > max_dist: max_dist = dist point = e return point
(1)先读取表中的数据
(2)如何随机获取其中一个点作为第一个聚类中心
(3)接下来每次获取距离之间所有聚类中心点最远的点作为下一个聚类中心点
(4)每次迭代时,遍历集合中的所有点,将其加入距离最小的聚类中心点数组中,更新聚类中心
(5)最后将数据可视化,返回分类好的数组
def k_means(k):
# 读取数据
kmeans_data = np.genfromtxt('kmeans_data.txt', dtype=float)
# 初始化
r = np.random.randint(len(kmeans_data) - 1)
k_arr = np.array([kmeans_data[r]])
class_arr = [[]]
for i in range(k - 1):
k_arr = np.concatenate([k_arr, np.array([farthest(k_arr, kmeans_data)])])
class_arr.append([])
# 迭代聚类
n = 20
class_temp = class_arr
for i in range(n): # 迭代次数
class_temp = class_arr
for e in kmeans_data: # 把集合中的每一个点聚到离它最近的类
k_idx = 0 # 假设距离第一个聚类中心最近
min_d = distance(e, k_arr[0])
for j in range(len(k_arr)): # 获取距离该元素最近的聚类中心
if distance(e, k_arr[j]) < min_d:
min_d = distance(e, k_arr[j])
k_idx = j
class_temp[k_idx].append(e) # 把该元素加到对应的类中
# 更新聚类中心
for l in range(len(k_arr)):
k_arr[l] = means(class_temp[l])
# 将数据可视化
col = ['red', 'blue', 'yellow', 'green', 'pink', 'black', 'purple', 'orange', 'brown']
for i in range(k):
plt.scatter(k_arr[i][0], k_arr[i][1], linewidths=10, color=col[i])
plt.scatter([e[0] for e in class_temp[i]], [e[1] for e in class_temp[i]], color=col[i])
plt.show()
# 返回分类好的簇
return class_temp(1)遍历k值的范围,从1到9
(2)kmeans获取分类好的数组
(3)遍历kmeans计算对应的SSE
(4)画出对应k值的SSE的折线图
# 通过肘部观察法获取k值
def getK():
mean_dist = []
for k in range(1, 10):
# 获取分成k簇后的元素
kmeans = k_means(k)
sse = 0
# 计算SSE
for i in range(len(kmeans)):
mean = means(kmeans[i])
for e in kmeans[i]:
sse += distance(mean, e) ** 2
mean_dist.append(sse)
# 化成折线图观察最佳的k值
plt.plot(range(1, 10), mean_dist, 'bx-')
plt.ylabel('SSE')
plt.xlabel('k')
plt.show()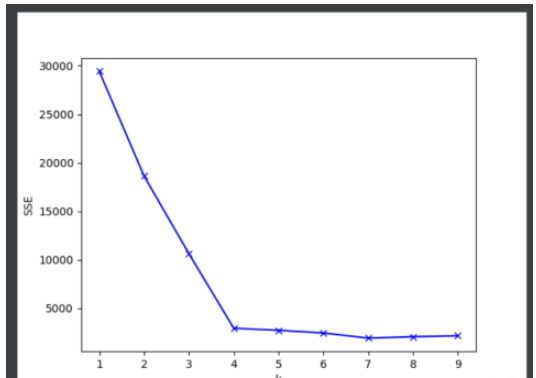
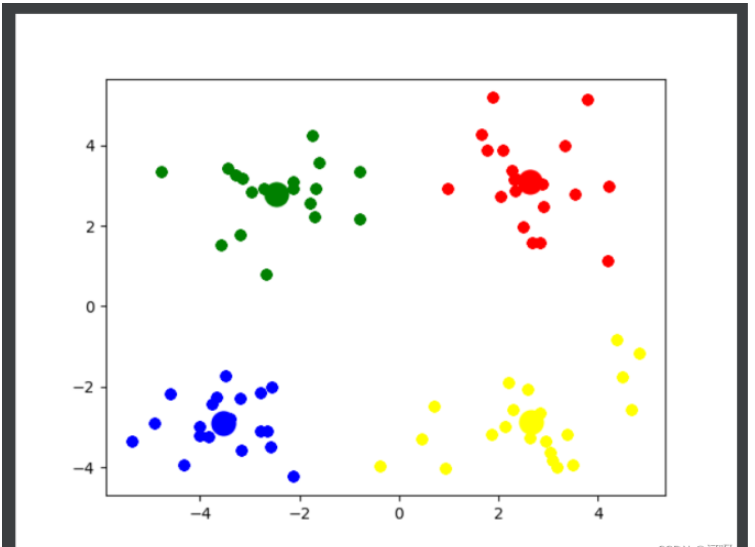
if __name__ == '__main__': getK() # 通过观察可知, 4 是最佳的k值 k_means(4)
import matplotlib.pylab as plt
import numpy as np
# 计算两点距离
def distance(a, b):
return np.sqrt((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2)
# 取集合中心点
def means(arr):
x = 0
y = 0
for i in range(len(arr)):
x += arr[i][0]
y += arr[i][1]
if len(arr) > 0:
x /= len(arr)
y /= len(arr)
return np.array([x, y])
# 寻找距离已加入聚类中心数组最远的点,用于初始化聚类中心
def farthest(k_arr, arr):
point = [0, 0]
max_dist = 0
for e in arr:
dist = 0
for i in range(len(k_arr)):
dist += distance(k_arr[i], e)
if dist > max_dist:
max_dist = dist
point = e
return point
def k_means(k):
# 读取数据
kmeans_data = np.genfromtxt('kmeans_data.txt', dtype=float)
# 初始化
r = np.random.randint(len(kmeans_data) - 1)
k_arr = np.array([kmeans_data[r]])
class_arr = [[]]
for i in range(k - 1):
k_arr = np.concatenate([k_arr, np.array([farthest(k_arr, kmeans_data)])])
class_arr.append([])
# 迭代聚类
n = 20
class_temp = class_arr
for i in range(n): # 迭代次数
class_temp = class_arr
for e in kmeans_data: # 把集合中的每一个点聚到离它最近的类
k_idx = 0 # 假设距离第一个聚类中心最近
min_d = distance(e, k_arr[0])
for j in range(len(k_arr)): # 获取距离该元素最近的聚类中心
if distance(e, k_arr[j]) < min_d:
min_d = distance(e, k_arr[j])
k_idx = j
class_temp[k_idx].append(e) # 把该元素加到对应的类中
# 更新聚类中心
for l in range(len(k_arr)):
k_arr[l] = means(class_temp[l])
# 将数据可视化
col = ['red', 'blue', 'yellow', 'green', 'pink', 'black', 'purple', 'orange', 'brown']
for i in range(k):
plt.scatter(k_arr[i][0], k_arr[i][1], linewidths=10, color=col[i])
plt.scatter([e[0] for e in class_temp[i]], [e[1] for e in class_temp[i]], color=col[i])
plt.show()
# 返回分类好的簇
return class_temp
# 通过肘部观察法获取k值
def getK():
mean_dist = []
for k in range(1, 10):
# 获取分成k簇后的元素
kmeans = k_means(k)
sse = 0
# 计算SSE
for i in range(len(kmeans)):
mean = means(kmeans[i])
for e in kmeans[i]:
sse += distance(mean, e) ** 2
mean_dist.append(sse)
# 化成折线图观察最佳的k值
plt.plot(range(1, 10), mean_dist, 'bx-')
plt.ylabel('SSE')
plt.xlabel('k')
plt.show()
if __name__ == '__main__':
getK()
# 通过观察可知, 4 是最佳的k值
k_means(4)以上就是关于“Python怎么通过手肘法实现k_means聚类”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注捷杰建站行业资讯频道。
本站采用系统自动发货方式,付款后即出现下载入口,如有疑问请咨询在线客服!
售后时间:早10点 - 晚11:30点
 服务热线 19970861797
服务热线 19970861797

 返回顶部
返回顶部