本篇内容主要讲解“ChatGPT前端编程源码分析”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“ChatGPT前端编程源码分析”吧!
程序运行视图:
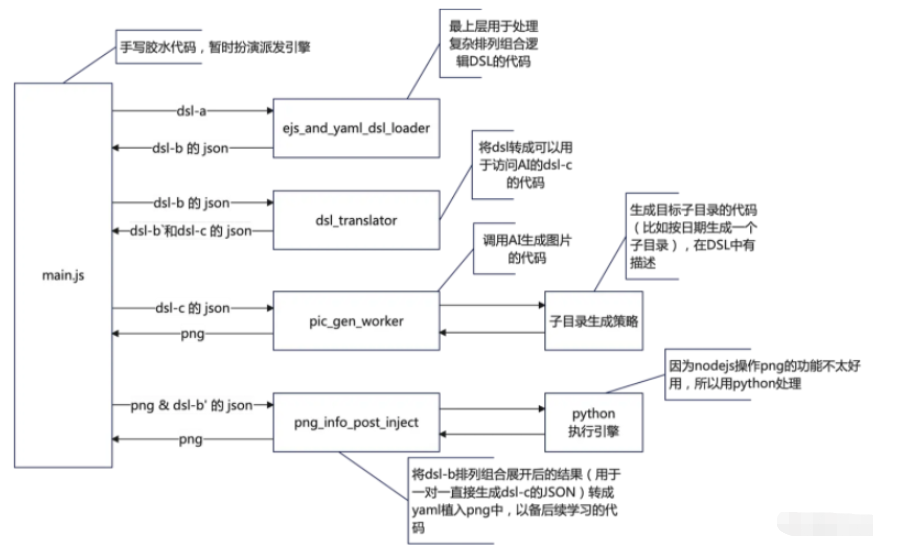
带着TDD思路,我进入了 ejs_and_yaml_dsl_loader 这个模块,这块因为我切的不是很好,所以这代码有点难写,不过没关系,正好我们实际工作大部分的场景都是这样的。看看我们在这里能玩出点什么来。
那么这次的需求呢是这个样子的,我们需要把ejs模版引擎渲染出的yaml转换为json,那么我们这个功能会非常复杂,所以我们没有以上来就去做ejs的部分。而是先从yaml的部分入手。如果只是yaml转json的话其实没什么意思,一行代码就实现了,关键是yaml里面有一个语法叫做json指针。
这个东西很重要。我们之前画的那个图还是有一点点。简化的我们只画了竖向的分层。但是在横向上,如果你要实现像我们说的,按照规模进行分解的话,如果一个case比较简单的话,还比较好办。通常我们的case会变得越来越复杂。可能就需要把它拆成多个。DSL文件,然后最后通过一个dsl把它组装起来。为了实现这种组装的能力呢,我们就要支持类似的语法,那么压帽里的jason指针的恰好是这样一个很好用的语法。当然他有他的一些缺陷,他可能不支持动态的参数,这个是我们后面的扩展。具体的json指针语法什么样的?一会大家看我们的prompt就知道了。
之所以需要这个语法以及它的扩展语法,是因为还记得咱们说的我们需要一个派发引擎吗? 其实派发与组合不过是动态和静态的区别。派发引擎也需要一套组合逻辑。而我们现在做这个功能就是为未来我们可能能实现一个派发引擎积累一些经验。
而我们使用的库呢,他不是原生支持JSON指针。他不支持呢,也挺好,因为我们后面会扩展这个功能。如果他支持的话,我们自定义的语法扩展起来反而很麻烦。背景知识就是这些,我们开始实现,下面试提问prompt:
我要用nodejs实现一个yaml的loader函数,可以读入yaml转为json,并且可以将其中JSON指针语法转换为具体的值.
这是base.yml:
- item: $ref: "/refed.yml#simple_value_keya" - item: keya: $ref: "/refed.yml#simple_value_keya"
这是在同一路径的refed.yml
simple_value_keya: value_of_keya
两个yaml文件都在一个文件夹里,比如叫yaml
而js文件与yaml文件夹同级
我期望的输出为:
[{
"item":"value_of_keya"
},{
"item":
{
"keya": "value_of_keya"
}
}]我还希望:
这个函数是async的。
读取文件的fs,要使用const fs = require('fs/promise')引入。
用js-yaml库解析yaml。
解析JSON指针的过程需要被封装为一个专门的函数。
代码要怎么实现?(直接给出最后的代码就可以)
结果给我生成了很长的代码:
const fs = require('fs/promises');
const yaml = require('js-yaml');
/**
* 从JSON指针中获取对应的值
* @param {Object} obj - 要获取值的对象
* @param {string} pointer - JSON指针
* @returns {any} 对应的值
*/
function getValueByPointer(obj, pointer) {
const parts = pointer.split('/').slice(1); // 去掉开头的'#'字符,然后拆分为路径的数组
return parts.reduce((acc, cur) => acc[cur], obj); // 依次按路径访问对象属性
}
/**
* 读取指定路径的YAML文件,并解析其中的JSON指针
* @param {string} path - YAML文件的路径
* @returns {Promise<any>} 解析后的JSON对象
*/
async function loadYamlFile(path) {
const content = await fs.readFile(path, 'utf8'); // 读取文件内容
const data = yaml.load(content); // 解析YAML为JSON对象
// 遍历JSON对象,查找$ref属性
const processRef = async (obj) => {
if (typeof obj === 'object' && obj !== null) { // 如果是对象
if ('$ref' in obj) { // 如果包含$ref属性
const refPath = obj.$ref.split('#')[0]; // 获取引用文件路径
const pointer = obj.$ref.split('#')[1]; // 获取JSON指针
const refData = await loadYamlFile(refPath);
const value = getValueByPointer(refData, `#${pointer}`); // 获取引用文件中对应JSON指针的值
return value;
} else { // 如果不包含$ref属性,递归处理子属性
for (const prop in obj) {
obj[prop] = await processRef(obj[prop]);
}
}
}
return obj;
};
return await processRef(data); // 处理JSON对象中的$ref属性
}
// 调用loadYamlFile函数并输出结果
(async () => {
const data = await loadYamlFile('./yaml/base.yml');
console.log(JSON.stringify(data, null, 2));
})();不出意外的,这个代码他是错的,我让他反复生成了很多次,结果总是差那么点,说实在的,差那么点我自己手改也不是不能改,但是胜负欲起来了。不能完全生成这个事还是有点让我感觉不爽,考虑到如果真的在实际场景中使用的话,这50行的长度也写不了太复杂的东西,但是一到这个长度,就没法细调整了太致命了,这又不是人,我不能指着这一行跟他说,这里有问题……嗯?指着这一行?我顿时灵光一闪。
在日常开发中,我们是怎么通过文字指出某一行有问题呢?答案再明显不过了:通过注释。而且,下面两个注释已经是约定俗成的使用方式了:
// TODO: 表示后续需要新增的功能,或其他任务项
// FIXME: 表示这里有Bug要修复
使用这两个注释,你甚至不用过多解释,你只要告诉他你用这个注释标了出来,让他按要求修改即可。
所以我就这么给他说:
下面代码不能满足我的需求,我会用//TODO: 来标记问题所在行
const fs = require('fs/promises');
const yaml = require('js-yaml');
/**
* 从JSON指针中获取对应的值
* @param {Object} obj - 要获取值的对象
* @param {string} pointer - JSON指针
* @returns {any} 对应的值
*/
function getValueByPointer(obj, pointer) {
const parts = pointer.split('/').slice(1); // 去掉开头的'#'字符,然后拆分为路径的数组
return parts.reduce((acc, cur) => acc[cur], obj); // 依次按路径访问对象属性
}
/**
* 读取指定路径的YAML文件,并解析其中的JSON指针
* @param {string} path - YAML文件的路径
* @returns {Promise<any>} 解析后的JSON对象
*/
async function loadYamlFile(path) { //TODO: 这个path参数需要作为递归读取时的的workdir,具体需求见下一个TODO
const content = await fs.readFile(path, 'utf8'); // 读取文件内容
const data = yaml.load(content); // 解析YAML为JSON对象
// 遍历JSON对象,查找$ref属性
const processRef = async (obj) => {
if (typeof obj === 'object' && obj !== null) { // 如果是对象
if ('$ref' in obj) { // 如果包含$ref属性
const refPath = obj.$ref.split('#')[0]; // 获取引用文件路径
const pointer = obj.$ref.split('#')[1]; // 获取JSON指针
const refData = await loadYamlFile(refPath); //TODO: refPath 通常是相对于当前yaml文件的,需要拼接一个指定的前缀作才是正确的路径,这个前缀通常是path参数自己的directory路径前缀,比如"./yaml/base.yaml"则是"./yaml"
const value = getValueByPointer(refData, `#${pointer}`); // 获取引用文件中对应JSON指针的值
return value;
} else { // 如果不包含$ref属性,递归处理子属性
for (const prop in obj) {
obj[prop] = await processRef(obj[prop]);
}
}
}
return obj;
};
return await processRef(data); // 处理JSON对象中的$ref属性
}
// 调用loadYamlFile函数并输出结果
(async () => {
const data = await loadYamlFile('./yaml/base.yml');
console.log(JSON.stringify(data, null, 2));
})();上面代码,这一行写错了:
const refPath = path.resolve(workdir, obj.$ref.split('#')[0]); // 获取引用文件路径
应该用path.join
给我完整的代码
通过这样的方式,我初步到了我想要的代码。之所以用TODO而不用FIXME,是因为我站在他的视角,把这个场景定义为了扩展新功能,而不是修bug。说某一行写错那个确实应该用FIXME,但是我怕混在一起会出错,而且后面已经有注释了,我不知道删掉好不好,毕竟注释也是帮他理解我代码的一种方式,所以单拎出来说了。
这个玩法不见得要那么精准,有的时候可能代码太复杂了,你可能看不出来哪里有Bug,毕竟不是你写的,也很正常,但是通过调试或者失败的测试数据,你能收敛到一个函数或者一个代码块,也可以通过这个方式来编写prompt。
比如下面这个:
给下面代码种FIXME标记的函数处有一些bug:
module.exports = function render_my_yaml_dsl(data){
const vm = require('vm');
// 定义一个函数用于渲染字符串模板
function render_string_template(originalScriptTemplate, intention) {
const execScriptTemplate = "`" + originalScriptTemplate + "`";
const script = new vm.Script(execScriptTemplate);
const execScript = script.runInNewContext(intention);
// console.debug(execScript);
return execScript;
}
// 定义一个函数用于展开属性组合
function expand_attributes(attributes) { // FIXME: 这个函数有bug
const result = [];
attributes.forEach(obj => {
Object.values(obj).forEach(val => {
if (Array.isArray(val)) {
val.forEach(v => {
result.push({ ...obj, [Object.keys(obj).find(key => obj[key] === val)]: v });
});
} else {
result.push(obj);
}
});
});
return result;
}
const polys = [];
for (const poly of data.poly) {
const { template_prompt, ...other } = poly;
const { template, meta } = template_prompt;
const variableGroups = expand_attributes(meta);
const prompts = variableGroups.map(variables => render_string_template(template, variables));
for (const prompt of prompts) {
polys.push({ prompt, ...other });
}
}
const result = polys.map(poly => ({ ...data.base, ...poly }));
return result;
}给定的输入: //....省略json数据
期望的输出应该是: //....省略json数据
而实际上是把数组里唯一的元素重复了8遍, 我需要修正这个错误,但同时,对于给定的输入: //....省略json数据
我还希望得到输出 //....省略json数据
结合这两个需求,请问代码哪里有错误?代码应该怎么写?
上面我省略掉了输入输出的数据内容,方便大家聚焦于我在代码上标记了FIXME(看,这个prompt对人也工作^_^)。这里是我写完ejs_and_yaml_dsl_loader之后,把所有代码集成起来运行的时候发现了一个bug,但是我也不知道bug是什么?(其实是懒得去看,用这个玩意久了,人真的是会变懒)所以我直接让他告诉我Bug是什么,然后怎么改,我来评估它的方案,在评估方案的过程中我就搞明白了bug是什么。这个效率可高了很多。
这个技巧不仅可以用于编程领域。在编程领域呢,我们取了个巧,恰好有注释和两个配合注释使用的关键字以表达我们的意图,这些东西我们不用告诉ChatGPT,它已经学习写程序的时候学过了。如果是在编程之外,可能我们要教他我们使用的标记是什么意思。 比如,我前一阵跟朋友们讨论要设计一个ChatGPT编程秀,在今天这个时代了,我们就想让ChatGPT帮我们设计,于是我们问:
我准备进行一个ChatGPT编程秀,给大家展示怎么用ChatGPT进行编程,时间为一个小时,可不可以给我一个编程秀的设计,并且附上时间安排.
于是我得到了下面的输出:
ChatGPT 编程秀设计
阶段 1:介绍 ChatGPT(10 分钟)
介绍 ChatGPT,包括其基本原理、应用场景、优缺点等。
演示如何使用 OpenAI API 调用 ChatGPT。
以一个简单的例子说明 ChatGPT 的使用,比如生成一句话。
阶段 2:生成文本(20 分钟)
介绍如何使用 ChatGPT 生成文本,包括如何控制生成文本的长度、样式等。
演示如何用 ChatGPT 生成一篇文章,比如一篇新闻稿。
演示如何用 ChatGPT 生成一组对话,比如模拟一次客服对话。
阶段 3:生成代码(20 分钟)
介绍如何使用 ChatGPT 生成代码,包括如何控制生成代码的复杂度、风格等。
演示如何用 ChatGPT 生成一段简单的代码,比如一个打印 "Hello, World!" 的程序。
演示如何用 ChatGPT 生成一段复杂的代码,比如一个排序算法的实现。
阶段 4:Q&A 互动(10 分钟)
与观众进行问答互动环节,回答关于 ChatGPT 的任何问题。
总结(5 分钟)
简要总结 ChatGPT 的特点和应用场景。
感谢观众的收看。
很明显,我们是个编程秀,所以我们不需要阶段2,所以我说:
这是一个编程秀,所以只要设计编程的环节就可以了
然后他回复:
ChatGPT 编程秀设计
阶段 1:介绍 ChatGPT(5 分钟)
简单介绍 ChatGPT 的基本原理和应用场景。
阶段 2:生成文本(20 分钟)
演示如何使用 ChatGPT 生成一段文章,比如一篇新闻稿。
演示如何使用 ChatGPT 生成一组对话,比如模拟一次客服对话。
阶段 3:生成代码(25 分钟)
演示如何使用 ChatGPT 生成一段简单的代码,比如一个打印 "Hello, World!" 的程序。
演示如何使用 ChatGPT 生成一段复杂的代码,比如一个排序算法的实现。
阶段 4:优化代码生成(10 分钟)
介绍如何调整 ChatGPT 的参数来优化生成的代码质量。
演示如何优化前面演示的代码生成。
阶段 5:Q&A 互动(10 分钟)
与观众进行问答互动环节,回答关于 ChatGPT 的任何问题。
总结(5 分钟)
简要总结 ChatGPT 的特点和应用场景。
感谢观众的收看。
可以看到,并没有删除,这可能是大多数人在面临对长文本进行反馈时都会面临的尴尬了,驾驭不住ChatGPT,非常的难受。 于是我这样做:
我会用代码注释的形式在内容上标记给你反馈 ,比如"// FIXME: "表示这里有问题,冒号后面会跟随我要修改的意图。下面是我的输入:
ChatGPT 编程秀设计
阶段 1:介绍 ChatGPT(5 分钟)
简单介绍 ChatGPT 的基本原理和应用场景。
阶段 2:生成文本(20 分钟) // FIXME: 我不需要这个阶段2,
演示如何使用 ChatGPT 生成一段文章,比如一篇新闻稿。
演示如何使用 ChatGPT 生成一组对话,比如模拟一次客服对话。
阶段 3:生成代码(25 分钟)
演示如何使用 ChatGPT 生成一段简单的代码,比如一个打印 "Hello, World!" 的程序。
演示如何使用 ChatGPT 生成一段复杂的代码,比如一个排序算法的实现。
阶段 4:优化代码生成(10 分钟)
介绍如何调整 ChatGPT 的参数来优化生成的代码质量。
演示如何优化前面演示的代码生成。
阶段 5:Q&A 互动(10 分钟)
与观众进行问答互动环节,回答关于 ChatGPT 的任何问题。
总结(5 分钟)
简要总结 ChatGPT 的特点和应用场景。
感谢观众的收看。
就得到了这样的输出:
ChatGPT 编程秀设计
阶段 1:介绍 ChatGPT(5 分钟)
简单介绍 ChatGPT 的基本原理和应用场景。
阶段 2:生成代码(35 分钟)
演示如何使用 ChatGPT 生成一段简单的代码,比如一个打印 "Hello, World!" 的程序。
演示如何使用 ChatGPT 生成一段复杂的代码,比如一个排序算法的实现。
介绍如何调整 ChatGPT 的参数来优化生成的代码质量。
演示如何优化前面演示的代码生成。
阶段 3:Q&A 互动(10 分钟)
与观众进行问答互动环节,回答关于 ChatGPT 的任何问题。
总结(5 分钟)
简要总结 ChatGPT 的特点和应用场景。
感谢观众的收看。
是不是掌控感就强了许多?TODO也是可以用的,比如:
我会用代码注释的形式在内容上标记给你反馈 ,比如"// TODO: "表示我希望你改进的点,冒号后面会跟随我要达成的效果。下面是我的输入:
ChatGPT 编程秀设计
阶段 1:介绍 ChatGPT(5 分钟)
简单介绍 ChatGPT 的基本原理和应用场景。
阶段 2:生成代码(35 分钟)// TODO: 我希望整个阶段是用一个例子串起来的,请帮我设计一个具体的例子来进行这个阶段的演示,并重新设计这个阶段的子步骤
演示如何使用 ChatGPT 生成一段简单的代码,比如一个打印 "Hello, World!" 的程序。
演示如何使用 ChatGPT 生成一段复杂的代码,比如一个排序算法的实现。
介绍如何调整 ChatGPT 的参数来优化生成的代码质量。
演示如何优化前面演示的代码生成。
阶段 3:Q&A 互动(10 分钟)
与观众进行问答互动环节,回答关于 ChatGPT 的任何问题。
总结(5 分钟)
简要总结 ChatGPT 的特点和应用场景。
感谢观众的收看。
于是我就得到了:
ChatGPT 编程秀设计
阶段 1:介绍 ChatGPT(5 分钟)
简单介绍 ChatGPT 的基本原理和应用场景。
阶段 2:生成代码(35 分钟)
以一个例子串起来整个阶段的演示,比如:使用 ChatGPT 生成一个简单的数独求解程序。
首先演示如何使用 ChatGPT 生成一个基本的数独求解程序,包括生成伪代码和相应的 Python 代码。
然后演示如何使用 ChatGPT 生成一个更复杂的数独求解程序,包括优化算法和生成相应的代码。
最后介绍如何调整 ChatGPT 的参数来优化生成的代码质量。
注意,本阶段演示的例子不一定要是数独求解程序,可以根据需要选择其他适合的例子。
阶段 3:Q&A 互动(10 分钟)
与观众进行问答互动环节,回答关于 ChatGPT 的任何问题。
总结(5 分钟)
简要总结 ChatGPT 的特点和应用场景。
感谢观众的收看。
接下来我就可以基于数独游戏的例子是不是合适跟他展开对话了。这种方法是不是很强大? 通过这种技巧我可以针对性的对AI给我的内容进行反馈。
类比AI画图里,也有类似的技巧,叫做inpaint。比如众所周知,AI不擅长画手,所以呢就有人发明了这样的技巧
用PS涂抹一下大概的手的轮廓以表达意图
然后在AI里用标记工具把这个区域涂黑,并告诉他,这个区域是手
他就会基于我们涂抹的样子画一个手出来
这里Denoising strength设置的不够大,所以还不够清晰,但是可以看出这个意思。
同样的思想我们用在编程里就是上面的那个技巧了,类似于涂抹一个手的轮廓我还用过给他伪代码,比如在后面png_info_post_inject这个模块,生成测试框架的时候我就用过:
根据1.json中的数据结构,我需要把上面三个分支就可以简化为一个分支。
if (given.targetFile === '1.png') {
actualResult = await readPng(path.join(__dirname, 'cases', given.targetFile));
assert.deepStrictEqual(actualResult, then.expectedResult);
} else if (given.targetFile === '2.png') {
await writePng(path.join(__dirname, 'cases', given.targetFile), 'hello', then.expectedResult);
actualResult = await readPng(path.join(__dirname, 'cases', given.targetFile));
assert.deepStrictEqual(actualResult, then.expectedResult);
} else if (given.targetFile === '3.png') {
await updatePng(path.join(__dirname, 'cases', given.targetFile), 'hello', then.expectedResult);
actualResult = await readPng(path.join(__dirname, 'cases', given.targetFile));
assert.deepStrictEqual(actualResult, then.expectedResult);
}伪代码如下:
if(given.type!=='read'){
await png_info[given.entrypoint](given_file_path, given_params);
}
actualResult = await readPng(given_file_path);
assert.deepStrictEqual(actualResult, then.expectedResult);这个伪代码执行的时候,第一次可能不让我满意,但是我可以根据他生成的继续修改这段伪代码,很快就得到了我想要的代码。所以说,语言就是语言,编程语言也是语言,也可以用在prompt里。
到此,相信大家对“ChatGPT前端编程源码分析”有了更深的了解,不妨来实际操作一番吧!这里是捷杰建站网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
本站采用系统自动发货方式,付款后即出现下载入口,如有疑问请咨询在线客服!
售后时间:早10点 - 晚11:30点
 服务热线 19970861797
服务热线 19970861797

 返回顶部
返回顶部